Spending too much time optimizing for loops
This is part of a series of blog posts relating my experience pushing the performance of programming language interpreters written in Rust.
what? also, who?
My PhD is on the runtime performance of AST interpreters: my job is to try to make things go fast. Last year, we published the paper “AST vs Bytecode: Interpreters in the Age of Meta-Compilation”, where we compared AST and bytecode interpreters written on top of two different meta-compilation systems: GraalVM (a partial evaluation approach, relying on the Java language) and RPython (meta-tracing approach, in RPython, a Python subset). We concluded that AST interpreters performed surprisingly well, despite the widespread opinion that bytecode is the superior approach to interpreter design.
Though one question we received a lot was: are AST interpreters only good on meta-compilation systems that rely on higher-level languages, and not REAL PROGRAMMING LANGUAGES like C or Rust where I can do all my fancy optimizations?
So I’m trying, with Rust specifically, to get interpreters to perform as well as our existing ones - maybe better??? As part of his MsC here at the University of Kent, Nicolas Polomack wrote the som-rs interpreters, one being AST-based and the other BC-based, and he honestly did a tremendous job. However, the focus wasn’t so much on performance, and there’s a lot of effort needed to push it further. How much exactly? Well, here’s how much I improved the performance of the AST and BC interpreters after a few months of implementing various optimizations and fixing performance bugs:
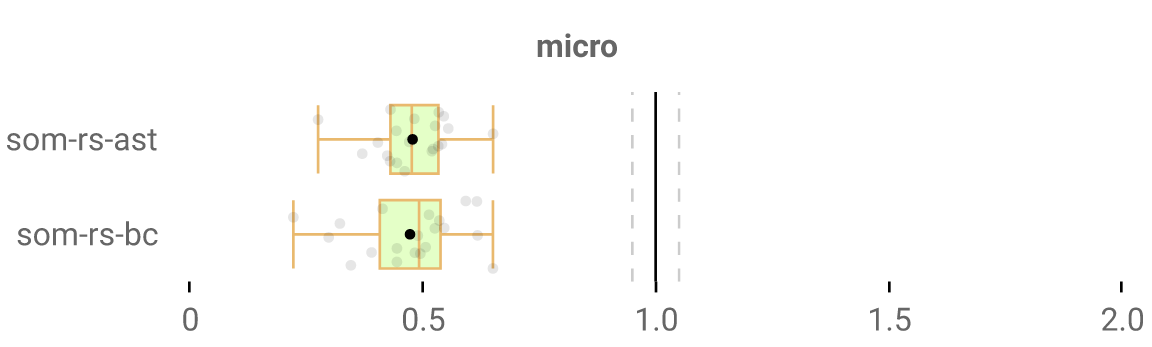
How to read the graph: each grey dot is one of our benchmarks, and lower is better. A 0.5x median speedup means we’re twice as fast, as we can see here, so not bad. (small disclaimer: only showing results on our micro benchmarks for my own convenience, but results are extremely similar on our macro benchmarks).
And this is where we’re currently at, compared to the interpreters we used in our paper:
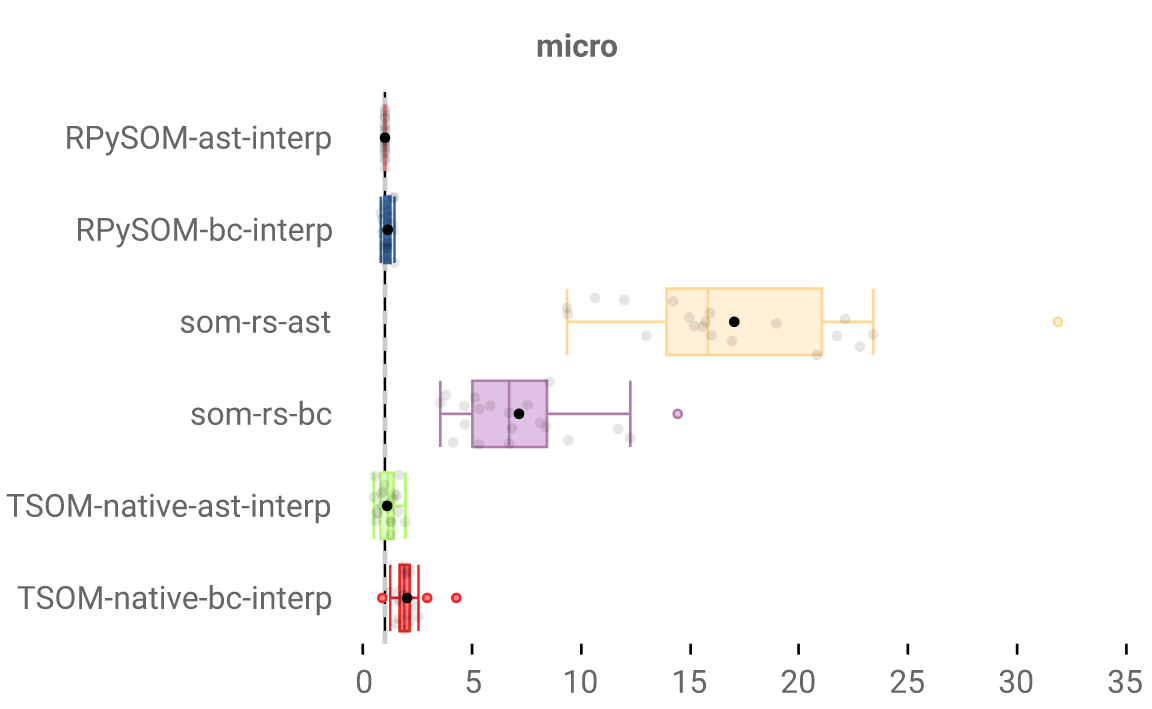
A long ways to go still… The BC one is getting there, progress with the AST one is slower for various reasons, including Rust limitations - there’s some interesting stuff to talk about there, maybe in a future blog post.
As a disclaimer, I’m not a real Rust dev, and I’m in fact a disgusting poser and a sham. My experience with the language before this consists of small personal projects, and were mostly about me getting my bearings with the many foreign concepts introduced by Rust. Having suffered with C for years 1, I tend to assume other programming languages will always be smooth to use and learn by comparison, but Rust feels like a different beast.
I have been loving my time as a Rust dev, though! It’s a great language and really pleasant to work with. At other times unpleasant to work with when you want to get high performance and ownership rules get in your way… More on that at some point.
what happened this week?
We’re working with interpreters for the SOM language, a minimal Smalltalk designed for research and teaching. It being based on Smalltalk means that everything under the sun is an object, and so that method calls on said objects are absolutely everywhere. Say your code has a loop:
[ iter > 0 ] whileTrue: [ iter := iter - 1. ]
…spoilers, it’s in fact a method called on the Block class (the condition block) that takes in another block (the loop body) as an argument. Its code looks like this:
whileTrue: block = (
self value ifFalse: [ ^nil ].
block value.
self restart
)
I won’t describe this code in detail. What matters is that in SOM, a loop is a method call, and that method calls need dispatching and are therefore not the fastest. It may sound like a counter-intuitive language design choice, but that’s the beauty of Smalltalk: you can re-implement every method yourself and fundamentally change the behavior of your system, like by making every loop invest in random cryptocurrencies to spice up both your VM and your life (please don’t do this).
can we speed that up?
That’s a cool feature, but 99.999999% of the time we want loops to be regular loops, so we should hard-code somehow to be treated as such to gain performance. This is typically the kind of stuff you can lower (handle at e.g. the bytecode-level or in the interpreter directly: anything to not interpret the code normally) to get better performance, and in fact we already do for whileTrue: (in the bytecode interpreter). I implemented some JUMP bytecodes, I inline the condition and body blocks into the method scope, and jump around to their starts and ends depending on what I want. Looks something like this:
0 | PUSH_LOCAL 0, 0
1 | PUSH_0
2 | SEND_2 1 (calling #>)
3 | JUMP_ON_FALSE_POP 5 (jump to idx 8)
4 | PUSH_LOCAL 0, 0
5 | DEC
6 | POP_LOCAL 0, 0
7 | JUMP_BACKWARD 7 (jump to idx 0)
8 | ...
Once again, the details don’t matter here. The big idea is that we jump past the body block when we’re done, and we jump to the condition block after we execute the body block. It’s pretty classic stuff, was surprisingly time-consuming to implement, but provided an unsurprisingly large amount of performance. Make every loop faster, and you speed up every program by a lot.
the to:do: method
But currently, we don’t handle every loop that way: a common way of looping is to call the Integer>>#to:do: method, invoked like 1 to: 50 do: [ ... ] . In case anyone’s curious, here’s its code (no need to look at it that closely):
to: limit do: block = (
self to: limit by: 1 do: block
)
to: limit by: step do: block = (
| i |
i := self.
[ i <= limit ] whileTrue: [ block value: i. i := i + step ]
)
to:do: is essentially a for loop and is consequently used very frequently, but it doesn’t get turned to specialized bytecode right now because I’ve only got so much time. Let’s finally speed it up!
Now, inlining calls and blocks at the bytecode level is nice, but another way of lowering code is to implement some function as a primitive: i.e. handling it as its own special case in the interpreter. Primitives are everywhere and unavoidable in PL implementation: just ask yourself how you would allow a program to perform a system call like time , and you’ll find making a primitive for it is a very sensible solution.
In this case, I’m confident that specialized bytecode would be faster, but I figured a primitive would be a quick and easy solution so I could move on to trying to squeeze (hopefully major) performance wins elsewhere. Especially since there’s Integer>>#to:do: but also Integer>>#to:by:do: and Integer>>#downTo:do: and Integer>>#downTo:by:do: and they all have different behaviors and I am lazy. I’d rather make them primitives with nearly identical code than wrap my head around how bytecode should be generated for each - we want an easy, in and out, 20 minute adventure (spoilers: I have forgotten Hofstadter’s law yet again)
So here’s our to:do: primitive:
fn to_do(interpreter: &mut Interpreter, _: &mut Universe) {
const SIGNATURE: &str = "Integer>>to:do:";
expect_args!(SIGNATURE, interpreter, [
Value::Integer(start) => start,
Value::Integer(end) => end,
Value::Block(blk) => blk,
]);
for i in start..=end {
todo!("execute the block every time");
}
interpreter.stack.push(Value::Integer(start));
}
expect_args! is a macro that pops arguments from the stack (because this is a stack-based bytecode interpreter, by the way) and checks their types. In this case, we expect three: if we’re calling 1 to: 50 do: [ ... ] , we expect start to be 1, end to be 50 and blk to be the body block.
Then from 1 to 50 (using Rust’s nice ..= inclusive range syntax), we’ll execute the body block somehow. Then every method returns its caller (self) when there’s no explicit return, which in this case is start (remember this is a method defined ON an integer class, which means self is an Integer with a value of 1!), so we put start back on the stack.
Neat. It’s missing a critical part though…
how do we execute that block?
The bytecode loop for som-rs is a big run method invoked once at the start of the program and which continues until execution ends. There’s a call stack of method/block frames that gets added onto throughout execution depending on what calls are made, and getting the current bytecode is just a matter of accessing the current frame (the last on the frames stack) and reading the bytecode from it that corresponds to the current bytecode index.
If the bytecode says you need to return from a function, you pop from the frames stack and so the current frame switches back to the previous one. To call a new function/block, you push a new function/block frame and it becomes the current frame.
So with that in mind, this primitive should just be a matter of pushing… 50 new block frames. Which doesn’t sound like the best way to go about it, but I can’t think of a better way to do it with of our bytecode interpreter design. Easy:
for i in (start..=end).rev() {
interpreter.push_block_frame(Rc::clone(&blk), vec![Value::Block(Rc::clone(&blk)), Value::Integer(i)]);
}
push_block_frame needs two arguments: the block to make a frame out of, and a vector containing the arguments it should be executed with. The first argument of a block is always itself, and to:do: semantics are that the block takes in the range index as an argument, so that’s why Value::Integer(i) is there.
Since a stack is last-in-first-out, we call rev() on the range so that we add the “50” block first on the frame stack and the “1” block last, such that we execute the “1” frame first, then the “2” frame, etc., all the way to “50”.
Job’s done, so we can just run it with a random benchmark and -
Starting QuickSort benchmark.
thread 'main' panicked at som-interpreter-bc/src/universe.rs:527:9:
does not understand: "verifyResult:"
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
- and we broke the interpreter somehow. Why?
This kind of error really just means “the stack got messed up and that caused the interpreter to panic somewhere down the line afterwards”. verifyResult: exists, it was just called on the wrong class because the stack didn’t contain the right values in the right order.
And that gives us a hint as to why it broke. Earlier I mentioned “every method returns its caller (self) when there’s no explicit return”: every single method or block returns something, which gets put on the stack. But in this case, we really don’t care about whatever the block returns, and the real to:do: pops it off the stack after each execution.
So we need to call POP after each block. The issue is that with our current interpreter design, there’s no easy way to inform the interpreter to do that. TruffleSOM and PySOM don’t have a single big run bytecode loop, and in fact call the bytecode loop function for each method individually, so it’s pretty easy to say “invoke this method and then discard its results” - just call run_bytecode_loop(method). No such luxury here.
selling my soul for performance
OK, here’s a fix: add an am_i_ugly flag to every frame, set it to true only for these specific to:do: frames, and whenever we pop a frame (i.e. we return from a block/function) if the frame had that flag, we pop a value off the stack to ignore its output. And that works pretty damn well: look at that speedup!
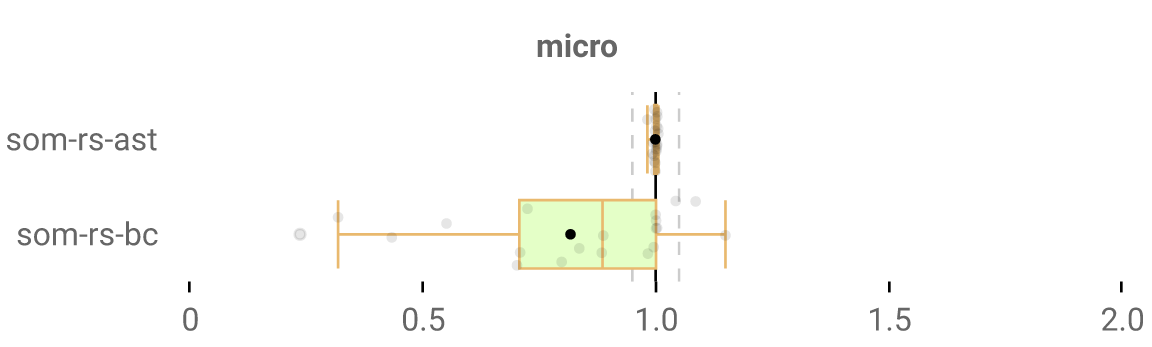
But I’ve got two major issues:
- A) this is ugly code and I hate it very much
- B) this is a slowdown in some odd cases - up to 15%. I assume that making every frame have a bigger/different layout prevents some compiler optimizations, or slows down accesses to frame info. I don’t know what’s happening specifically, but I’m sure of what caused it: this extra argument.
It’s a working solution though, so I went ahead and implemented the other variations like to:by:do: and downTo:do: and whatnot, to see what the total speedup was like. Which would be this:
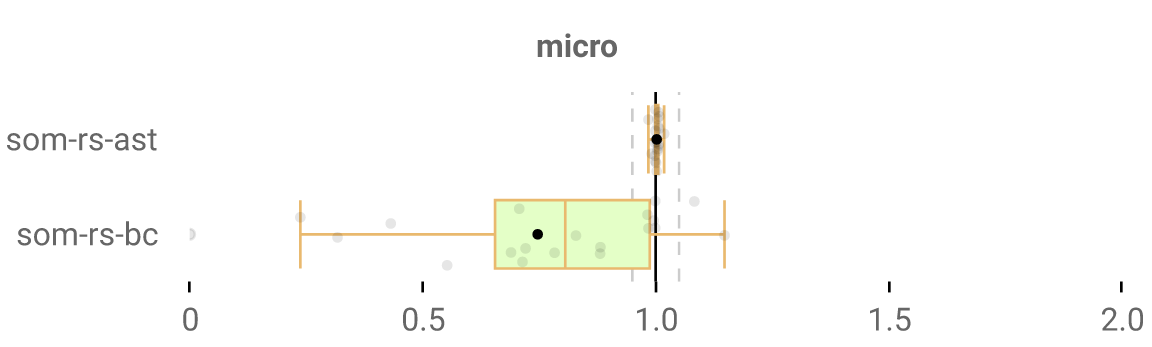
Looks reaaal good. A 100% speedup on one of our benchmarks even (one whose runtime is extremely dominated by a to:by:do: call)! The code sucks, but we’re at least on the right track.
So we’re back to the drawing board when it comes to informing the interpreter to clean up after some blocks. I guess we could also store some sort of state in the interpreter instead of in each frame, which would likely be faster and wouldn’t prevent compiler optimizations, but it’d be a pretty unclean solution and not as straightforward as one might think (we can’t just tell it: “do a POP after the next 50 frames”, because those to:do: frames may invoke nested blocks of their own, so it still needs to track info on a frame-by-frame basis).
a better solution
I’ve got a better idea: instead of executing the block as is, we execute a modified version of the block that cleans up after itself.
Say we’ve got this block:
PUSH_ARG 1, 1 # stack: [arg1-1]
PUSH_ARG 0, 1 # stack: [arg1-1, arg0-1]
SEND_2 0 # stack: [send-return-value]
RETURN_LOCAL # stack: [send-return-value]
I’ve described the stack state next to each bytecode. Any PUSH bytecode is naturally going to push something onto the stack; a SEND will consume arguments to emit a single return value; and a RETURN_LOCAL won’t touch the stack, it just pops a frame.
We want an empty stack, so we want to generate this new block right there instead:
PUSH_ARG 1, 1 # stack: [arg1-1]
PUSH_ARG 0, 1 # stack: [arg1-1, arg0-1]
SEND_2 0 # stack: [send-return-value]
POP # stack: []
RETURN_LOCAL # stack: []
So what we do is that instead of invoking the block, calling to:do: first creates a new block based on the existing one with a POP added before every RETURN, and we execute that instead! It’s kind of annoying since creating that block means checking which JUMP bytecodes need to be adjusted, since if we’ve got a JUMP 10 bytecode (meaning “jump to 10 instructions further”) and there’s a RETURN in the middle which we prepended with a POP , it now has to become a JUMP 11 to account for the new instruction.
Way more annoyingly, there is such a thing as a RETURN_NON_LOCAL in our bytecode set. I don’t have time to go into non-local returns (this article is long enough as is), but we want to actually keep whatever return value is associated with a non-local return on the stack, while making sure to remove the SECOND TO LAST value on the stack which corresponds to the self value that we want to clean up. So my supervisor suggested I add a POP2 bytecode which pops the second to last value off the stack, to easily do just that - and I did, and it worked.
This was confusing, hard to discover and understand, needed amending the goddamn bytecode set itself, and cost me many hours of my life that I’m never getting back :(
So the to:do: code is now:
let new_block_rc = blk.make_equivalent_with_no_return();
for i in (start..=end).rev() {
interpreter.push_block_frame(Rc::clone(&new_block_rc), vec![Value::Block(Rc::clone(&new_block_rc)), Value::Integer(i)]);
}
We could do even better: generating the block at compile-time instead of parse-time. When handling messages (function calls), if its name is to:do: or one of its friends, we would simply replace its block argument with our new, optimized one. Something pretty much like this:
if ["to:do:", "to:by:do:", "downTo:do:", "downTo:by:do:", "timesRepeat:"].iter().any(|s| *s == message.signature) {
match ctxt.get_instructions().last().unwrap() {
Bytecode::PushBlock(idx) => {
// find block from index "idx"
// call our new `make_equivalent_with_no_return()`;
// replace the block
},
_ => { todo!("uh... what's this case?") }
}
}
…except it’s not that simple, and this todo!("...") case highlights why. If the block is the result of a PushArgument or PushLocal or whatnot, we can only get access to it during the runtime. So this sadly isn’t an easily available option, which is a shame since it would net us up a median speedup of 8% or so. 2
So we keep our previous solution of creating modified blocks at runtime. OK, final results:
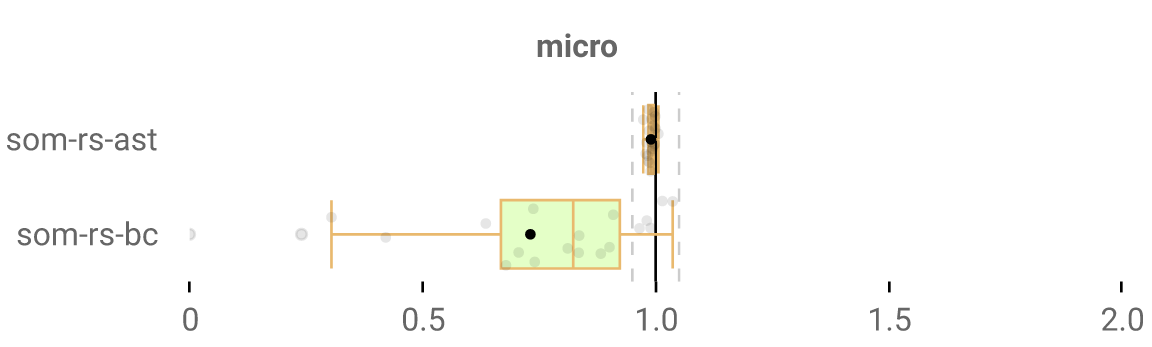
Massive speedups! It’s a very minor slowdown on one of our microbenchmarks and I’m not sure why - maybe it’s just noise.
so what have we learned?
- being mindful of the design of the interpreter itself matters, unsurprisingly. Choosing to have a single execution of a massive bytecode loop function, as opposed to designing the interpreter such that the bytecode loop function is invoked for each method call, makes things much harder in this context.
- It doesn’t sound like a bad design decision to me, but is it? It’s hard for me to tell since I’m lacking experience. Let me know more about why that’s a bad idea if you know!
- If not enough people point out to me that it is in fact a bad idea, I’d be interested to rebuild the bytecode interpreter to fix that design decision, and see if it’s faster. But I’d need to push the performance a lot more first.
- There’s a lot of performance to be gained from optimizing loop operations. It’s fairly obvious, but a solid chunk of the runtime will be spent in long-running loops: if you can make them all a bit smoother, you make runtime a lot faster.
- Aaaand the quick and easy solution is rarely quick or easy. This was never meant to be so arduous - this whole “let’s make a primitive function” idea was meant to take an hour tops to avoid spending a couple hours implementing it at the bytecode level, but it ended up taking much longer! I don’t think I could have easily predicted this seemingly easy change would be so hard: this requires a lot of knowledge about the system you’re working with and about interpreter design, yet I’m but a humble PhD student. We’re getting there though.
That’s about it. Thanks to Stefan Marr (my PhD supervisor) for the feedback and the help. I’ll post more stuff in the future. xoxo
-
This problem is far from unfixable. We could still instrument the blocks in the
PushBlockcase at compile-time and only instrument at runtime when we know it wasn’t instrumented at compile-time, but we’d need a way to differentiate instrumented from non-instrumented blocks. I’m thinking one good solution would be for primitives to check whether the last bytecode executed was aPushBlock, but our solution and this article are wordy enough as is… ↩