Adding garbage collection to our Rust-based interpreters with MMTk
This is a blog post about the garbage collection framework MMTk and my experience implementing it into our own Rust-based intepreters. We talk about Rust a lot here, but we forgo a lot of its guarantees, for better or for worse, but definitely for performance. To be clear, these are research projects and not production systems.
The goal of this blog post is to remain accessible, such that people with limited knowledge of GC or of Rust can still get value out of it. If you really want, you can jump directly to the MMTk introduction or the technical implementation bits and it will not hurt my feelings.
introduction: who? what?
the who and some of the what
The who is me. And this is part of a series of blog posts relating my experience pushing the performance of programming language interpreters written in Rust for my PhD. For a bit more context, read the start of my first blog post.
In short: we optimize AST (Abstract Syntax Tree) and BC (Bytecode) Rust-written implementations of a Smalltalk-based research language called SOM, in hopes of getting them fast enough to meaningfully compare them with other SOM implementations. The ultimate goal is seeing how far we can push the AST’s performance, the BC being mostly to be a meaningful point of comparison, which means its performance needs to be pushed by a similar amount.
As a general rule, all my changes to the original interpreter (that aren’t failed experiments) are present here…
…and benchmark results are obtained using Rebench, then I get performance increase/decrease numbers and cool graphs using RebenchDB. You can check out RebenchDB in action and all of my results for yourself here, where you can also admire the stupid names I give my git commits to amuse myself.
the rest of the what (“what have i been doing”)
It’s been ages since the previous blog post (six months / 7 years or so in dog years), so a lot of things happened, most of which are described in a daunting amount of commits.
The performance of both our AST and BC interpreters is much, much better: something like 100% (yeah!) for the AST and 70% for the BC. Both interpreters have been worked on extensively and even undertook major reworks, a lot of which are explained by this blog post’s subject: we now do garbage collection using MMTk, instead of relying of doing it using naive reference counting. To show off the performance from the GC changes specifically:
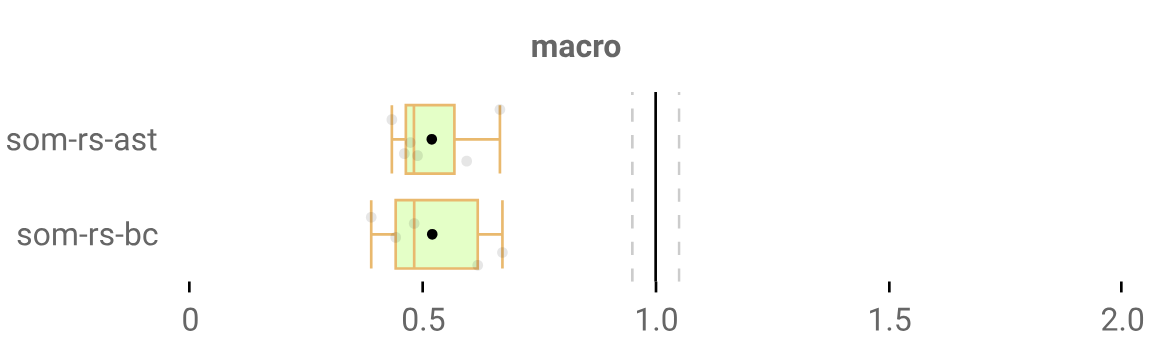
Double the speed, for both our AST and BC intepreters. As the ancient nugget of wisdom goes: “good shit”.
Though this data can easily be misleading! Importantly: this needed major interpreter reworks to function, so a lot of changes were made and not all of them are strictly related to MMTk itself or tracing GC. What do you do when you’re getting annoyed after a lot of GC debugging? You procrastinate by working on other features in your interpreter1. As a random example, I realized that I’d been using Vec::split_off in a very common case instead of the better-suited Vec::drain to get values out of some vectors. That’s a fun (probably) fact for you.
I should mention that the majority of such theoretically unrelated changes were made possible by changing our pointer representation to accommodate for tracing GC, though, so it is at least related.
But what did we change, and why?
reference counting: the existing, naive approach
We’ve got memory, we need pointers to it. The Rust pointer catalogue is pretty much:
- standard references with
&T(pointers which abide by Rust’s safety guarantees) - ugly raw pointers
*const T(bad boys which disregard safety guarantees) - or smart pointers, most notably
Box<T>,Rc<T>andRefCell<T>.
We were using smart pointers a lot since they also tend to own the data they reference, which tends to be a lot more convenient than trying to pass references around everywhere.
The basic case is a Box<T>: it’s just a pointer to the heap, prettified and wrapped by Rust.
OK, SOM is object-oriented and so has Class objects, which we represent with Rust structs. Say in our interpreters any pointer to a Class object will be a Box<Class>. Instances of this class (Instance objects, also Rust structs) need a Class pointer to read static variables from it and… oh wait, Rust ownership rules say that data has a single owner. But we want each Instance to own a reference to the same Class, which is shared ownership, so a standard Box<T> doesn’t cut it.
So Rc<T> (which stands for reference counting) comes to the rescue: data can be referenced in several places, since we keep track of its users through a counter. When that counter reaches 0, the final user of that Rc<T> has sadly passed away, the data is no longer needed and so it’s discarded.
Or put another way: the counter informs us that the data is garbage, and it gets automatically collected.
Using Rc<T> is then a form of garbage collection, and one that’s very easy to implement and work with.
To give our pointer type a final tweak, these Class SOM objects have static variables, so we need mutable access to them, which is what RefCell<T> provides.
So the final pointer type we choose: Rc<RefCell<T>>. Very nice.
We can successfully access and modify pesky types like Class from many different places and so we have working interpreters, Rust manages all the memory for us and is happy, and we’re happy because Rust is happy and automatically manages all the memory for us and because Rust is happy. Everyone and everything is happy.
Except the runtime performance, which - as a reminder - is the thing we actually care about. Every single time we want to access e.g. a Class, we need to A) check that it’s not already mutably borrowed by somebody else, B) increment the reference count by 1; then every time we drop a Rc<RefCell<T>> after using it, we need to decrement the reference count by 1.
So pointer access is slow, and we do a lot of it. But we need some sort of garbage collection to manage our memory, and if reference counting doesn’t cut it, what can we do instead?
tracing garbage collection
Tracing garbage collection is another form of automatic memory management. It looks through all objects to determine which ones should be discarded. Our objects are all a big graph that starts with several roots, and GC traces it to see which objects are reachable: if you can no longer be found in the graph, you’re no longer in use and in the garbage you go.
Reference counting has to check whether or not to discard an object everytime we stop using a reference to it. Tracing GC just waits until we run out of memory, in which case we stop the world to stop running our code so that we can safely trace the object graph without it being modifiable mid-analysis2.
Reality isn’t as simple as “reference counting is slow, tracing GC is fast”, to be clear. Garbage collection is a massive field that’s been around for longer than you’ve been alive (author’s note: educated guess). You can find state-of-the-art reference counting collectors such as LXR, and hybrid counting/tracing approaches do exist. We’re not concerned with very advanced GC algorithms in our case, though: we don’t need state-of-the-art GC, but to move away from one of the simplest and slowest forms of garbage collection (naive reference counting).
In fact, the bulk of our performance of our performance gain isn’t from fancy GC but more from ditching Rc<T> to directly manage our own allocations on our own heap.
This is harder to work with since we dismiss ownership entirely, which is a core Rust feature, but now allocation can be made much faster. For GC algorithms that use a bump allocator, we can simply always keep a pointer to the next free element in the heap, and have allocation simply be bumping it up by the requested amount.
let new_cursor = self.alloc_bump_ptr.cursor + size;
if new_cursor < self.alloc_bump_ptr.limit {
let addr = self.alloc_bump_ptr.cursor;
self.alloc_bump_ptr.cursor = new_cursor;
addr
} else {
todo!("out of space, we need to collect garbage first")
}
(code simplified from an example in the MMTk docs)
So if we manage our own heap, but we set no upper limit to its size and we keep increasing it when it becomes full, then…
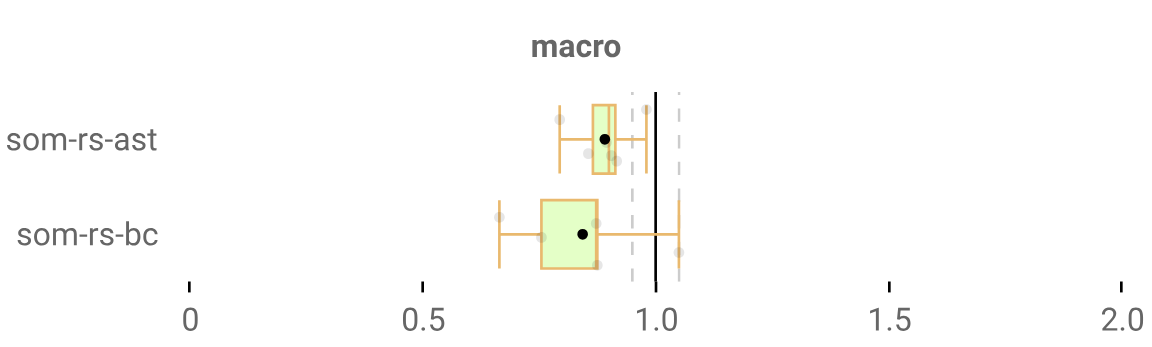
Pretty damn good speed just from ditching Rc<T>! But we’ve got no garbage collection happening.
This means to function for any program, we need an infinitely-sized heap, and right now for longer-running benchmarks our interpreters keep requesting more and more memory until the OOM killer comes in with the steel chair. And to be fair, I think RAM prices are going down, so maybe 1 billion gigs of RAM will be a reasonable ask in 2-3 years.
But until then, we need to actually periodically collect all that accumulating garbage in the heap, and that’s why we need some nice, efficient GC.
GC is hard
When stepping away from approaches like naive reference counting, it turns out that garbage collection is pretty damn hard to implement. Which at a glance may sound counterintuitive: the naive assumption is that you “just” need to:
- implement your own heap and a simple memory allocator for it
- some algorithm to collect the garbage
- and some way to scan that memory for data.
And sure, our naive Rc<T> approach was pretty much effort-free, but this doesn’t sound awful - probably.
The devil’s in the details, though. All three of these parts need to be sturdy for everything not to explode, and debugging any can be an ordeal. Your memory allocator has a bug and fails but only after a hundred thousand allocations? That’s rough, buddy. Now imagine if the bug also only happened sometimes, and you’ve got a certified #classic GC bug3. Also in the real world, that scanning part is extremely difficult in many cases, but hopefully our small virtual machine can be mostly fine.
And all this needs to be snugly implemented into your VM since you’ll want to be able to allocate anything from just about anywhere, which creates a pretty strong dependency on the GC and makes it extremely hard to reuse, and you’d best be sure you properly implemented it or you will find nasty bugs (more on that later…).
So looking back at our list, it sure would be nice if there was a language-agnostic framework to greatly simplify managing the GC heap, allocations, scanning and collections. In related news, MMTk is a language-agnostic framework that greatly simplifies managing the GC heap, allocations, scanning and collections.
mmtk overview
The project has been around since 2004. Here’s a great, short video introduction.
Through MMTk’s API and bindings, you can incorporate any of several pre-existing plans (garbage collection algorithms - mark and sweep, semispace, etc.) into your VM, or create your own plan. So you can easily support various GC algorithms, as opposed to tightly coupling your VM to any chosen GC approach; and all this in any language, AND while being fast. It’s really, really cool stuff. It’s got sturdy bindings for OpenJDK, V8, among others like for Julia or Ruby, so it clearly works with much larger virtual machines than mine.
My reasoning behind choosing MMTk for som-rs was:
- the promise of high performance, which is a high priority for us.
- the ability to easily switch between different GC strategies, because modularity makes me happy and so that I have the ability to evaluate the performance impact of different algorithms on my work if I want.
- not having to implement these GC strategies myself, since I know this would take me ages. I’m more used to metacompilation systems giving me GC for free than me implementing it myself…
- It is written in Rust! The previously mentioned bindings needed to deal with FFI, but we sure don’t.
Though with regards to it not taking ages to implement, software is war4 and all warfare is based on deception: therefore I unfortunately deceived myself with unreasonably short time estimates, and implementing GC did in fact took me several months (oops).
Though work on it was on and off, and the bulk of my time was spent on debugging classic GC implementation mistakes. This is a major motivation for this blog post: sharing my experience and my code, to help others get up to speed faster than I did.
All warfare is also based on planning, so the game plan was:
- get a basic mark-and-sweep GC working: it traverses the graph, finds and marks the garbage, sweeps it.
- once that implementation is sturdy, move up to a better-but-more-complex moving collector that can move data around. My pick was a semispace plan: heap split in two big chunks, garbage collection copies only live objects from one chunk to the other, that other chunk becomes the new “main” heap until garbage collection occurs again and we do it all the other way around.
Then once I’ve got a moving GC off the ground, I can also theoretically easily start using a better MMTk-provided GC plan like Immix. But I don’t actually need a crazy well performing GC, just one that’s good enough for my interpreters not to be much slower than they could be, in which case no meaningful conclusions could be drawn from their performance. So semispace should be good enough.
implementation: the new pointer type
For starters, the most obvious change to our existing design is our pointer representation. It’s no longer a Rc<RefCell<T>> type, but instead just a wrapper around a raw pointer to our own new object heap.
pub struct Gc<T>(*mut T);
This mean we don’t leverage Rust’s safety guarantees at all: it’s raw pointer city, and that sucks. There’s many blog posts on garbage collection out there that use more clever pointer types, like Saoirse’s shifgrethor, Core Dumped’s Emacs Lisp VM or kyren’s gc-arena.
We don’t, since it was already a major hurdle to get my interpreters working correctly with tracing GC, and I’m not sure how I’d add nice lifetimes to them. These interpreters are a solo dev research project with neither unlimited funding nor time, so I sometimes cut corners so long as performance is optimal.
Anyway, we’ve now got our own heap pointer wrapper. Thanks to Rust’s type system, we can implement Deref/DerefMut on it to be able to access its underlying data as if it were a &T/&mut T, avoiding a lot of boilerplate code and making it a proper smart pointer.
impl<T> Deref for Gc<T> {
type Target = T;
fn deref(&self) -> &T {
debug_assert_valid_heap_ptr!(self);
unsafe { &*self.0 }
}
}
We’ve obviously been moving away from normal Rust and all its guarantees, which is annoying, but there’s another nice example of how we can still leverage the type system to our advantage. A wrapper has the clear benefit of providing explicit, zero-cost meaningful differentiation between an arbitrary pointer and a pointer to an object in our heap.
But it’s got an another major advantage for debugging: we can check that our pointers are valid whenever we dereference them (only in debug builds).
Our debug_assert_valid_heap_ptr macro verifies that we’re indeed pointing into our heap and not to random data, so that we didn’t mess up many many cycles ago.
let bad_ptr: Gc<usize> = Gc::from(4242);
let a: usize = *bad_ptr + 1; // will break! pointer found to be invalid.
This is a godsend when using garbage collection plans that can move your data around: if our safety check sees you’re pointing to data that has since been moved, you forgot to update that pointer when moving, and you’ve got a bug5. More on moving GC later.
implementation: mmtk’ing
Now, let’s explore the API. You are expected to memorize everything in this section and there will be a test at the end - or you could skim through it if you’re not looking to implement it yourself.
MMTk provides the very helpful DummyVM to showcase interactions with its API (described here), which I used as a base - and you probably should too.
It assumes we want to do FFI, and so has a lot of e.g. extern "C", but we don’t even need all that since we never exit Rust.
To interact with MMTk, we need an MMTk instance. For that, we create a builder with our chosen options and our pre-existing MarkSweep plan, then we call mmtk_init::<SOMVM>(&builder) to get a nice MMTK<SOMVM>.
We also need to declare a mutator, a per-thread data structure to manage allocations, so an incredibly important one.
We call mmtk_bind_mutator to ask MMTk to please give us a Mutator<SOMVM> for our current and only execution thread, which we’ll store and use to allocate memory. And now we’re all sorted.
But that SOMVM didn’t come out of nowhere, did it? That’s the name we’ve given to our VM in our big VMBinding with MMTk, a binding which looks like this:
impl VMBinding for SOMVM {
type VMObjectModel = object_model::VMObjectModel;
type VMScanning = scanning::VMScanning;
type VMCollection = collection::VMCollection;
type VMActivePlan = active_plan::VMActivePlan;
type VMReferenceGlue = reference_glue::VMReferenceGlue;
type VMSlot = SOMSlot;
type VMMemorySlice = mmtk::vm::slot::UnimplementedMemorySlice<SOMSlot>;
}
And now there’s a lot going on. Here’s what everything means:
VMObjectModel: how objects are represented.- The defaults here worked well for me. My main change was implementing the
copyfunction, since semispace needs to copy objects.
- The defaults here worked well for me. My main change was implementing the
VMScanning: how to scan the object graph. Boils down to implementing two of the most important functions, which we’ll elaborate on soon:- the
scan_objectfunction to scan any object in your VM. - …and the
scan_rootsfunction to tell MMTk what the roots are. Very nice.
- the
VMCollection: methods for garbage collection. The only needed ones are:block_for_gc: stop the world to let a collection happen. For us, it’s pretty much just using aCondVarto stop our main and only mutator thread.stop_all_mutators: stop all mutator threads. We’ve only got one andblock_for_gchas already stopped it, so we just tell MMTk to go ahead.spawn_gc_thread: spawn a thread that MMTk will used for GC. In our case, just a glorifiedstd::thread::spawncall.resume_mutators: notify that sameCondVarthat GC has occurred, and that we can go back to executing our code.
VMActivePlan: methods to tell MMTk how to access mutators, to which we happily provide it our storedMutator<SOMVM>reference.VMReferenceGlue: for reference processing (like weak references) and finalizers.VMSlot: aSlotis roughly just a reference to an object. MMTk providesSimpleSlotwhich works for most cases, but we did need to make our ownSOMSlothere (explained in a later bit)VMMemorySlice: to represent abstract memory slices. As the “unimplemented” indicates, I never implemented that either, though.
All done. A simple allocation would then look like:
let new_ptr: Address = mmtk_alloc(&mut mutator,
size_requested,
GC_ALIGN, // (alignment): 8 for us
GC_OFFSET, // (offset): 0
AllocationSemantics::Default);
When we request too much memory and GC gets triggered, we’ve provided everything we need for MMTk to stop the world, scan our object graph and clean up our mess.
Additionally, we say AllocationSemantics::Default to indicate we’ve got no special requirement for this object, but we’ve got other options such as requesting it to be Immortal so that it’s never collected, NonMoving to never be moved, or Los to allocate large objects specifically.
List of options here.
This is a simple, slow-ish way of allocating, which we can also make faster such as with that bump allocator example earlier, instead of ever calling mmtk_alloc directly. That doesn’t work for our marksweep since this GC strategy doesn’t use a bump allocator, but it will be useful for semispace.
When allocating an object, we also reserve a space in the header for storing a magic number corresponding to its type.
When MMTk visits the object graph, we need to know somehow how to interpret any sequence of bytes: did we allocate a Class or a Frame or a String there?
So we declare an enum ObjType that has variants for all the possible objects.
In our VM, that’s only 10 possible types or so, but we annoyingly (and pretty naively6) still need to use a full usize to store it for alignment reasons.
So now our program can allocate any type with an associated ObjType, and we’ll be able to reify types during scanning, which we’ll implement now.
scanning
First, we need to tell MMTk what the object graph roots are, through VMScanning’s required scan_roots_in_mutator_thread function. Here’s a simplified version of our code:
fn scan_roots_in_mutator_thread(_tls: VMWorkerThread, mutator: &'static mut Mutator<SOMVM>, mut factory: impl RootsWorkFactory<SOMSlot>) {
let roots = get_roots_in_mutator_thread();
factory.create_process_roots_work(roots);
}
fn get_roots_in_mutator_thread() -> Vec<SOMSlot> {
unsafe {
let mut roots: Vec<SOMSlot> = vec![];
// walk the frame linked list
let current_frame_addr = &(*UNIVERSE_RAW_PTR_CONST).current_frame;
roots.push(SOMSlot::from(current_frame_addr));
// iterate through the globals list
for (_name, val) in (*UNIVERSE_RAW_PTR_CONST).globals.iter_mut() {
if val.is_ptr() {
roots.push(SOMSlot::from(val.as_ptr()));
}
}
roots
}
}
…which showcases another ugly aspect of our GC implementation: our core Universe class contains globals, core classes, basically all our roots.
But MMTk needs access to those roots somehow, so we keep a pointer to our universe available for MMTk as a global static variable, bypassing ownership rules of not having a mutable and immutable reference active at the same time… I’m not sure how to avoid this, to be honest - ideas welcome if you have any.
Roots are reported as slots, which we call SOMSlot. To quote the documentation:
A Slot represents a slot in an object (a.k.a. a field), on the stack (i.e. a local variable) or any other places (such as global variables). A slot may hold an object reference. We can load the object reference from it, and we can update the object reference in it after the GC moves the object.
A slot is essentially then memory that can contain an reference. MMTk provides a SimpleSlot type that’s effectively a *mut Address, so a pointer to a pointer to an object.
The *mut part might sound redundant: an Address type would be enough to report where references are. And it would be enough for our MarkSweep implementation, but only because it can never move objects: but as the documentation indicates, we need to be able to mutate that address because we might want to update those references to newly moved objects.
As an example, here’s our block type:
pub struct Block {
// Reference to the captured stack frame.
pub frame: Option<Gc<Frame>>,
// Block environment needed for execution
pub blk_info: Gc<Method>,
}
Both frame and blk_info are pointers. When moving GC happens, the frame and method referenced will change addresses, so these fields need to be updated.
So we essentially report both &mut blk.frame and &mut blk_info (so &mut Gc<T> types, equivalent to a *mut Address) as slots, and MMTk takes care to update the references.
As seen in the code, our roots are pretty much just A) our frames and B) our global variables. We declare our globals as roots by iterating over the vector that contains them, which makes sense, but how come we only report one of our many language frames?
That’s because our second scanning function scan_object, which is in charge of scanning any of our types, will take care of the rest. We’ve reported a frame object as a root to the object graph,
which means it will then be scanned to find out what its children are. When it scans any frame, we simply report the previous frame in the list to MMTk!
// read the object type from the object header
let obj_type: &ObjMagicId = VMObjectModel::ref_to_header(object_addr);
match obj_type {
ObjMagicId::Frame => {
let frame: &Frame = object_addr.as_ref();
// recursive frame scanning!
if let Some(prev_frame) = frame.prev_frame.as_ref() {
slot_visitor.visit_slot(SOMSlot::from(prev_frame));
}
// (...)
}
ObjMagicId::Instance => {
let instance: &Instance = object_addr.as_ref();
// visit class pointer
slot_visitor.visit_slot(SOMSlot::from(&instance.class));
// visit field pointers
for val in &instance.fields {
visit_value(val, slot_visitor)
}
},
_ => {
// (...) - handling of all other types
}
}
It’s not the prettiest7, but fairly simple logic overall. The real trouble is not forgetting to scan one pointer and be confused when it randomly breaks some time after execution resumes (which may or may not have happened to me several times).
We invoke slot_visitor.visit_slot(...) throughout this code to report slots to MMTk. But there are also calls to visit_value in there.
We have our own representation for values, which you’d think they would just be reportable as pointers in the same way, right?
Well, as it turns out, we need to take a closer look at slots to get it working.
custom slot types, and a little bit of nan boxing
We use Value to represent any, well… value. That’s a boolean, an integer, or a double, or perhaps a string, maybe an array, maybe a pointer to a block or an instance or a class.
We used to represent it as an enum like this.
pub enum Value {
Nil,
Boolean(bool),
Integer(i32),
String(Gc<String>),
Class(Gc<Class>),
Invokable(Gc<Method>),
// ...and more
}
…which was fine, but not as efficient as it could have been. A value was then 16 bytes: the biggest value possible was a pointer, so 8 bytes, but we need metadata to store its type, requiring an extra 8 bytes for alignment reasons. Which again is fine, but we can do better. Since in practice pointers don’t actually need all 8 bytes they’re given, we can use NaN boxing to make both a pointer and its type fit all in 8 bytes, and sneak in more performance that way.
pub struct Value {
encoded: u64,
}
We’re not going to spend yet more time explaining how it works in detail under the hood, but the answer is a lot of bit masking to get types and values in and out. To give proper credit, this NaN boxing implementation wasn’t my work but was in fact written by the original som-rs author though never merged properly. I did much tweaking to adapt it to my som-rs fork for the extra performance, but the core logic is still the same as his.
Now the question is: a slot is a pointer to a pointer. If our value is a u64 from which you can extract a hidden pointer, how do you make a reference to that pointer?
Well… we can get the pointer out of the Value and into a local variable, and make a SimpleSlot from a pointer to that local variable. Sure:
let inner_ptr: Gc<Class> = value.get_ptr();
let slot: SimpleSlot = SimpleSlot::from(&inner_ptr)
But what happens when Rust exists that scope? inner_ptr is reclaimed, and now accessing &inner_ptr doesn’t represent anything: we’ve caused undefined behaviour (woo).
So as it stands, we can’t report pointers hidden inside Value types to MMTk. Which is exactly why we need a new slot type, one that handles extracting and storing pointers from Values. Lo and behold:
pub struct RefValueSlot {
value: *mut Value,
}
A pointer to a Value, that’s it. Our slot type is now an enum to handle both possibilities:
pub enum SOMSlot {
Simple(SimpleSlot), // a `*mut Address` type.
RefValueSlot(RefValueSlot), // a `*mut Value` type.
}
And RefValueSlot’s associated code does the bit masking to do reads/writes in its Value:
impl Slot for RefValueSlot {
// read from the slot.
fn load(&self) -> Option<ObjectReference> {
unsafe {
ObjectReference::from_ptr((*self.value).extract_ptr())
}
}
// write to the slot: update the pointer when GC moved the object.
//
// to store the new pointer in the value, we just create a new one
// of the same type (tag) with that pointer
fn store(&self, object: ObjectReference) {
unsafe {
*self.value = Value::new((*self.value).tag(), object.extract_ptr());
}
}
}
And now we’re sorted. That visit_value from earlier can use a RefValueSlot, and we can report any and all pointers - even the ones hidden away in Value types.
When we’re given a SOMSlot, we can easily check if it’s a normal or Value slot, and call the according load/store methods.
moving collector: top 3 nastiest bugs
So far, we’ve been in the context of a MarkSweep GC, which is a non-moving collector. That’s already a hassle to get working when it entails massive VM refactoring like it did for me, but the real issue comes when you start allowing data to be moved around.
On the MMTk side, the main difference is having to implement the ObjectModel::copy function,
so that MMTk knows how to copy data to its new location in memory. Roughly speaking, that’s a glorified memcpy call - or std::ptr::copy_nonoverlapping::<u8> in Rust - and ObjectModel::get_current_size to tell MMTk how many bytes each object takes.
Which sounds much simpler than reality. Because the main addition of a moving collector is the implication that anything can move around, which introduces many pitfalls and many more bugs. MMTk does provide the helpful stress_factor option when building, which can trigger frequent stress GCs to help find nasty GC bugs, though.
Here’s a couple of bugs that manifested into reality in the past, though, nicely categorized. And everyone likes a list, so here’s a top 3.
number 3: badly copying
If it wasn’t already clear that for the sake of performance, we’d not exactly been writing the most idiomatic Rust code, let’s talk about our Frames having self-referential pointers (ew).
When we allocate frames, we know how many Values they’re going to need: we know how many arguments and local variables there are in the scope a frame represents, and for our stack-based bytecode interpreter, we’ve precomputed the maximum stack size possible when executing their associated bytecode. So with N total values, we can give them all an N-times-Value-sized little heap of their own like [(maybe Stack)|Arguments|Locals], for fast access and hopefully make our CPU happier, which we store directly after the Frame so that we can do one single, bigger allocation.
I’d made the frames store pointers to the areas of their mini heap that contain arguments and locals respectively, for faster access to them. Now I’m actually not positive it’s a strict speedup over frequently doing frame_ptr + size_of::<Frame>() + (stack_len * size_of::<Value>()) at runtime to access arguments/locals, but that was the assumption.
Those pointers are self-referential-ish, so they get invalidated when copying: if the Frame moved from 0x00040000 to 0x00080000, the pointers need to be changed from e.g. 0x00040010 to 0x00080010. This led to needing to implement an adapt_post_copy function of my own to adjust them.
Copying correctly also means reporting the correct size of data structures when you can’t do a simple size_of::<T> call to get that info. That means not messing up when implementing get_current_size/get_size_when_copied, which MMTk relies on to get the size of the copied objects.
number 2: oops stack variables
That one also applies to non moving GCs, but a moving one made it a lot worse. People talk about the issues that come from forgetting to scan the stack; I know about these issues because I’ve read the work of said people; this did not stop me from forgetting to scan many, many values on the stack.
Pointers to heap objects need to be able to be found by GC scans: if they don’t, they can now be pointing to already collected data. Most notably, when you’ve got variables in local variables (so on the Rust stack), they need to remain reachable somehow.
That was an occasional issue in our MarkSweep collector, though not incredibly frequent since a lot of our data remains valid throughout execution: we don’t have class unloading, so your Gc<Class> pointer will be safe everywhere. I used a few ugly hacks for the few parts that struggled with issues like these, and that did the trick.
Now consider a moving collector: any reference not found by GC is now incorrectly pointing to the wrong heap. Sneakily, a lot of the time, that’s enough to work for longer than you’d think: we don’t erase the old heap8, so it still contains valid data that you can mistakenly access.
Consider a case where you forget to update some pointers to the variable foo. You can do a foo = false operation only to have an assert foo = true work just fine shortly afterwards: because you accidentally wrote false to where foo was, on the old heap, while it’s actually equal to true on the new, correct heap. And to bend your brain more, if GC happens a second time and swaps both spaces again, your incorrect pointer to foo into what was the old heap is now a valid pointer into the current heap, but now to some random data in it and so all hell does break loose.
These bugs are why debug_assert_valid_heap_ptr (our macro mentioned much earlier that checks pointers point into the right heap) was made, and why I am proud to call it a dear friend. Adding it to Deref checks every pointer access and you can easily identify pointers you missed when scanning.
The BC interpreter is mostly fine since just about every Value in it ends up pushed on an easily accessible custom stack. But the AST interpreter doesn’t fare as well, since it was making extensive use of the Rust stack. As an example, here’s how we dispatch a method with two arguments:
impl Evaluate for TernaryDispatchDispatchNode {
fn evaluate(&mut self, universe: &mut Universe) -> Return {
let receiver = self.dispatch_node.receiver.evaluate(universe);
let arg1 = self.arg1.evaluate(universe);
let arg2 = self.arg2.evaluate(universe);
self.dispatch_node.lookup_and_dispatch(receiver, arg1, arg2, universe)
}
}
We evaluate the method’s receiver, the two arguments we want to call it with, and then we dispatch it. Simple enough.
But we need to consider than any evaluate call can trigger GC: if evaluating arg1 or arg2 triggered a collection, then the receiver pointer is now wrong: it was in a local variable on the Rust stack, which scanning cannot find.
The current fix is pretty ugly, as well as slightly slower: we keep a big Vec<Value> stack, and all variables we work with are pushed onto it, instead of being stranded as local variables. Then GC just checks/updates everything in that big self-made stack.
The “superior” fix would be to get a pointer to the Rust stack and manage that myself, which also involves flushing the contents of all registers to the Rust stack when collection is triggered… Which involves inline assembly, is wildly unsafe and is just begging for bugs, but also would be faster and would be pretty fun. Future work, maybe.
number 1:
Actually, that one is far worse. So:
a bug so nasty it escaped the previous section
This was a crash only in release builds, only on one unremarkable benchmark. It was so nasty that I thought it was definitely a bug in Rust itself, but as it turns out, it’s most likely a feature.
The bug was: shortly after GC triggers, a segmentation fault happens because we’re accessing invalid data. It’s clear that the issue is that some data does not get moved correctly even after collection. I put on my detective hat and tracked it down to a specific function, which allocates a new frame:
pub fn alloc_frame_from_method(
method: &Gc<Method>,
prev_frame: &mut Gc<Frame>,
gc_interface: &mut GCInterface,
) -> Gc<Frame> {
let mut frame_ptr: Gc<Frame> = gc_interface.request_mem(FRAME_SIZE);
*frame_ptr = Frame::from_method(*method);
let args = prev_frame.stack_pop_n_last_elements(nbr_args);
Frame::init_frame_post_alloc(frame_ptr, args, max_stack_size, *prev_frame);
frame_ptr
}
A bit simplified for your viewing pleasure. What we do is:
- we request memory, which might trigger GC.
- we write a new
Frameto that memory. - we pop arguments off the previous frame 9…
- …and write them to the new one (plus other unimportant post allocation stuff)
The incorrect behavior is: in some cases, when we trigger GC here, the prev_frame argument still points to the old heap, having seemingly not been correctly adapted by GC. So args that reads from it ends up being wrong, Frame::init_frame_post_alloc is given an incorrect pointer, and things break later.
The question is now: why?
Clearly, prev_frame is not properly reported to MMTk and doesn’t get moved. Simple, except it’s wrong: this Frame very much does get moved.
In fact, this very Gc<Frame> is the current_frame, who was even declared as an explicit root back in the scanning section.
We’re also dealing with a &Gc<Frame>, so a reference to a Gc<Frame> and not just some Gc<Frame> pointer left all alone dangling on the Rust stack.
If Gc<Frame> gets moved, a reference to it should still point to the right data.
So what’s the fix? After some soul searching, sanity questioning and much mixing of both, I did find a solution:
pub fn alloc_frame_from_method(...) -> Gc<Frame> {
// what
std::hint::black_box(&prev_frame)
// ...
std::hint::black_box. Which is:
An identity function that hints to the compiler to be maximally pessimistic about what black_box could do.
Basically, we tell the compiler not to optimize based on prev_frame.
If we read ahead a bit…
Note however, that black_box is only (and can only be) provided on a “best-effort” basis. The extent to which it can block optimisations may vary depending upon the platform and code-gen backend used. Programs cannot rely on black_box for correctness, beyond it behaving as the identity function. As such, it must not be relied upon to control critical program behavior.
Well, shit.
But our fix is just a temporary solution anyway, right? This is clearly a bug in Rust, who incorrectly assumes it can optimize code related to prev_frame.
And then I was given this link to notes by Manish Goregaokar (thanks Jake for making me aware of it!). This states:
One fundamental principle that I want to preserve is what I call “The Frozen Reference Property”: library code can safely assume that a reference
&'a Tcan be treated as accessible memory of typeT, with a constant address for the extent of the lifetime'a.
This is most likely the culprit, and exactly the kind of thing I would have loved to know months ago.
As to why it doesn’t break for the similar type &Gc<Method> next to it, or it only being in a few benchmarks, who knows…
Hell, I’m not even sure that a raw pointer instead of a reference actually fixes that problem. Out of the few benchmarks that break without the black_box call… only one is fixed by using a raw pointer instead? So this exemplifies more that Rust optimizations are really not aware, or caring, about the possibility of moving GC.
So this makes me very much aware that Rust might choose to break my GC implementation in future releases. I would rather not be forced to not update my Rust compiler, and I’d rather not have to go back to using C++…
This is the kind of thing that you’d find in the language spec, with the exception that there’s no proper spec out for Rust at the moment. There’s a team working on one, though, and I’m very much looking forward to it. I hope it’s of help to future people who want high-performance GC in Rust.
But anyway.
On the bright side, these three categories of bugs all make me grateful that I at least don’t have to handle the GC algorithm logic: I have the trusted MMTk implementations of GC algorithms that I can rely on. Trustworthy, in fact, since I’ve not found bugs in them myself: all of the bugs discussed above in my VM have been of my own doing (yay?).
That’s about it for the bugs, so it’s about time we wrap it up.
EDIT: an important safety disclaimer
Except let’s not wrap it up quite yet, because… I’m not positive that my interpreter is sound, at the moment. I was made aware of some issues with my design after putting this blog post online (help for which I’m grateful!), and these issues need to be addressed.
In short, DerefMut is dangerous because having several mutable references is unsound in Rust, hence this very nasty bug I mentioned in the last section.
This means it’s all too easy to write almost-functional code but with subtle bugs, without proper use of UnsafeCell and friends.
So I need to write my solutions and thoughts down, which will likely turn into a new blog post somewhere down the line. It’s been hard to find the time to do this, since I’ve not had much time to work on som-rs because I’ve got other, less fun priorities…
Anyway, disclaimer done, and will properly address this someday.
some technical disclaimers
Before finishing: there’s a lot we didn’t try and there’s a lot we don’t support. GC is complicated, having a GC in Rust is complicated, and life also tends to be complicated.
- we never explicitly do finalization. That’s a usually major point of complexity when doing GC, and to be honest one that I’m all too happy to circumvent.
- arbitrary data on the Rust heap can’t reference
Gc<T>pointers. We can storeGc<T>types on the Rust heap if we know exactly where to find them (e.g.Universe.current_frame), but we never get into any situations where we would want to do any sort of tracing in the Rust heap itself to find our data.- This isn’t enforced: you could make and use a
Box<Gc<T>>, but your computer would explode after GC happens. As far as I’m aware, it’s impossible to enforce without modifying Rust itself. (EDIT: not quite - it is possible! Lifetimes enable this)
- This isn’t enforced: you could make and use a
- our interpreters are single-threaded. Making GC work with multi-threaded interpreters is likely to add more bugs, and more work.
in conclusion
We saw:
- a rough overview of garbage collection
- how you can make it work with Rust (and how Rust can sometimes hate it)
- and more specifically, how one would implement it using MMTk.
GC is a complex topic, so that took a while and I still wasn’t thorough at all.
MMTk is a great concept with clearly solid execution, about which you’ve hopefully now got enough knowledge to get started more more easily. It does a large chunk of my job for me, though the complexities of GC are still apparent when using it, sp there’s still a myriad of ways to mess up. Which is why you’ve hopefully learned from some of my own mistakes!
My own implementation could use a lot more work and has some hacky bits, but it sure does make my interpreters run, and it should serve as a nice starting point. You can find the latest version of it here.
This whole thing took a while to write, so I’d like to thank Stefan Marr for the feedback, and the MMTk team for both proofreading and the helping hand when implementing their framework.
Thanks for reading if you did. If you didn’t, I’m not thanking you, but you still have my respect.
Goodbye for now
-
I might write a more thorough analysis of each experiment of mine in the future if I muster the courage to dig through all my data + if I can make it interesting. And look, you yourself also procrastinate by implementing new features instead of fixing bugs. ↩
-
Some GCs don’t stop the world, but that’s a whole other level of complexity so we don’t do it. There’s no reason you couldn’t use MMTk for that, though. ↩
-
If that happens, I hope you’re well aware of record and replay debugging. ↩
-
On a metaphysical level, everything is war and love - probably. I had philosophy classes back in high school, so I must know what I’m talking about. ↩
-
OK, technical clarification for people familiar with GC: it could still very much work since you’d find a forwarding pointer on the old heap which you could use to access the new data, but that indirection would be a slowdown, so we want everything copied onto the new heap without exception to maintain fast access to it. ↩
-
In some cases the type information is encoded in the object, which we could definitely use. ↩
-
I’m thinking the best way would be to have each object implement some
VisitByGctrait with their associated visit logic, to associate eachObjMagicIdwith a given type in a nice way and to do dynamic dispatch. Another TODO for the future… ↩ -
I learned too late that in non-release builds, you really should erase the old heap by overriding it with recognizable values like
0xdeadbeeffor easier debugging. Though my debug macro that checks pointers does achieve a similar effect anyway. ↩ -
Which, by the way, is how we keep those arguments reachable when GC happens. They’re not on the Rust stack, but safe in the previous frame. That’s also why we only pop them after GC might have occurred. ↩